Устали работать в СНГ с высокими валютными рисками? Хотите попробовать себя на более конкурентных рынках? Решили вывести свой бизнес в США?
Для решения любой из этих задач вам предстоит разобраться с англоязычной семантикой и формированием технических заданий для копирайтеров. Здесь вам не поможет Яндекс.Wordstat и Планировщик ключевых слов Google, здесь нужен алгоритм посерьезней.
Хотите иметь растущую аудиторию из поисковых систем? В этой статье вы узнаете как подобрать поисковые запросы и составить грамотное техническое задание англоязычным копирайтерам🦾
Анализ конкурентов
Выбор ниши — это тема для отдельной статьи. Предположим, что мы решили сделать простой сайт для сбора трафика по информационным запросам в нише Relationships. Это популярная и стабильная ниша в США:

и в мире:
С устоявшимся спросом:
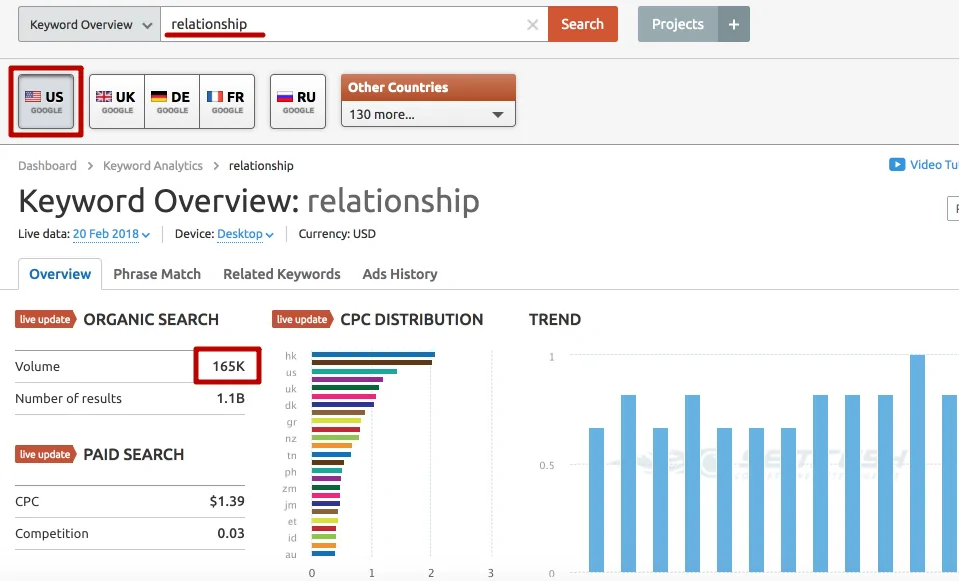
Ниша средней конкуренции, но при этом в ней присутствуют крупные сайты:
- psychologytoday.com;
- glamour.com;
- nytimes.com;
- gq.com;
- prevention.com;
- cosmopolitan.com;
- huffingtonpost.com;
- ted.com.
Им по 10-20 лет и это далеко не полный список. Выбирайте, какие сервисы для seo анализа конкурентов лучшие использовать в вашем случае.
Тем не менее, есть понимание, что в этой нише можно работать. Согласны?
Нет?
И правильно. Давайте посмотрим на наши аргументы.
Итак, какая перед нами стоит цель — найти низко- и средне- конкурентные запросы.
Выбор кластеров запросов
Задача на текущем этапе — выбрать главные запросы статьи. 1 запрос = 1 статья. На следующих этапах мы будем подбирать второстепенные запросы и расширять.
Путь 1. Исследование запросов
1. вводим в semrush целевой запрос и переходим во вкладку Phrase:
2. перейти во вкладку “Phrase Match” и применить фильтр:
Где Volume (частотность запросов) и Keyword Difficulty (конкуренция запроса) могут меняться в зависимости от ниши.
Получаем выборку:
В которой есть как информационные запросы, так и коммерческие.
Также на этом этапе можно подметить типовые запросы связанные с memes и quotes:
Например, возьмем запрос “memes for her”:
Очень привлекательные запросы с низкой конкуренцией и хорошим спросом.
Запросы, у которых конкуренция ниже 60, можно считать низкоконкурентными, но конечно, такие выводы нужно делать в отношении других запросов в нише. Ниже мы рассмотрим различные варианты анализа конкуренции запросов.
Запомним эти запросы и перейдем к следующему варианту поиска низкоконкурентных запросов.
Путь 2. Анализ молодых сайтов.
- найти нишу, в которой есть свежие молодые сайты с трафиком;
- понять их семантику и посмотреть, можем ли мы ее применить для своего проекта.
Поиск ниш осуществляется перебором. Рассмотрим процесс изучения на примере relationships.
1. выбираем несколько запросов из нашей нише, например:
- funny relationship memes;
- cute relationship quotes;
- relationship memes for her.
2. выгружаем сайты, которые ранжируются по этим запросам:
3. экспортируем и объединяем результаты выдачи по разным запросам в одну таблицу:
Semrush отдает топ 100 результатов выдачи, иногда меньше.
4. загружаем домены в checktrust.ru:
5. определяем возраст, трафик, количество страниц в индексе Яндекса и траст по majestic:
ждем…
6. сортируем по дате регистрации домена:
7. смотрим на соотношение даты регистрации и трафика, отмечаем интересные сайты:
8. строим отчет по самым посещаемым страницам в semrush:
Для сравнения смотрим в ahrefs:
и serpstat:
Эти страницы могут не совпадать, особенно для молодых и не очень крупных сайтов.
9. изучаем семантику этих страниц и ищем потенциально интересные запросы — с хорошим спросом и невысокой конкуренцией.
Идя таким перебором, мы можем найти интересные запросы.
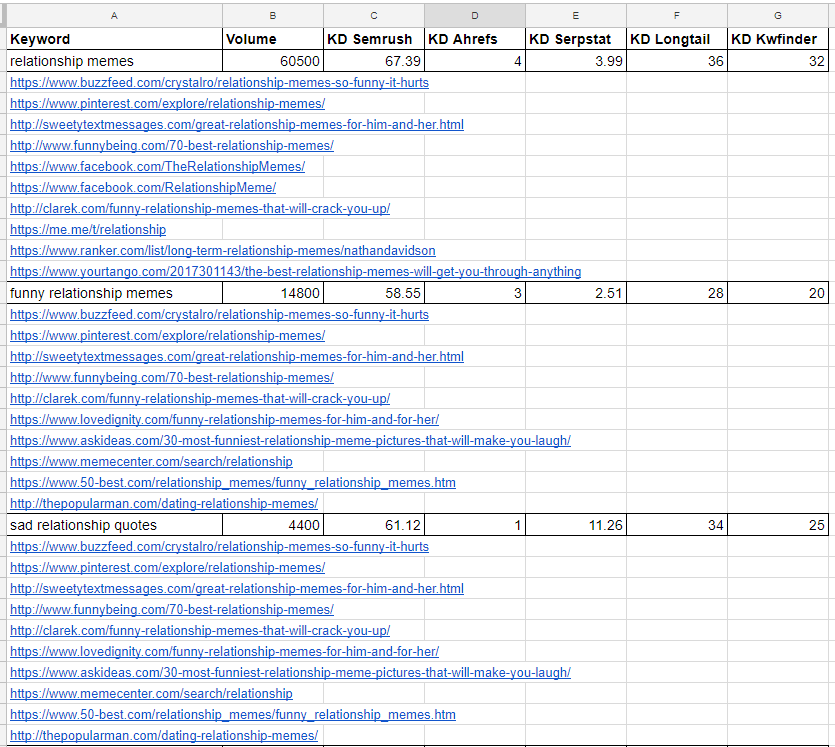
Для дальнейшего изучения берем следующие киворды:
| Keyword | Volume | KD |
| relationship memes | 60500 | 67.39 |
| funny relationship memes | 14800 | 58.55 |
| sad relationship quotes | 4400 | 61.12 |
| relationship memes for him | 2400 | 57.35 |
| stages of a relationship | 8100 | 68.51 |
| cute names to call your girlfriend | 8100 | 57.94 |
| questions to ask your girlfriend | 22200 | 50.49 |
| nicknames for boyfriend | 22200 | 58.20 |
| how to stop thinking about someone | 4400 | 60.16 |
| types of hugs | 1900 | 48.60 |
Специально отобрали запросы разного калибра, чтобы сравнить их между собой и выбрать лучшие.
Проверяем пересечение отобранных запросов
Зачем мы это делаем? Для экономии денег.
Если окажется, что по выбранным запросам у нас ранжируются одинаковые материалы, это значит, что мы напишем 2 статьи там, где можно было написать 1.
Самый простой способ — воспользоваться кластеризатором ключевых слов. Для примера возьмем rush-analytics.ru:
Выбираем регион США:
Выбираем soft кластеризацию:
Загружаем запросы:
Для этого потребуется создать xlsx файл и затем загрузить запросы в систему.
Проект обрабатывается:
По готовности заходим внутрь проекта. Во вкладке “Кластеризация” видим, что выдача по 3 запросам пересекается:
следовательно, мы их определяем в одну группу и будем готовить под них одну статью.
Во вкладке “некластеризировано” находятся остальные 7 запросов, у них пересечения по топу не были выявлены:
Оценка конкуренции запросов
Спросите зачем?
Снова же — для экономии.
Чем выше конкуренция запросов — тем больше усилий и профессионализма нужно, чтобы выйти в топ.
Существует большое количество сервисов для оценки конкуренции запросов на западных рынках.
Первый из них мы уже с вами использовали — semrush.com.
Но давайте изучим другие и сравним их результат оценки между собой.
Будем сравнить следующие сервисы для оценки конкуренции:
- ahrefs.com;
- semrush.com;
- serpstat.com;
- longtailpro.com;
- kwfinder.com.
А затем самостоятельно изучим топ по каждому запросу и посмотрим, кто точнее;)
Интересно?
Нам тоже. Поехали!
ahrefs.com
Все просто, вбиваем запросы:
получаем результат:
KD от 1 до 100.
serpstat.com
Вводим запрос в поисковую строку и получаем KD:
Очень большой недостаток — нельзя проверить конкретный список запросов. Поэтому придется все вбивать поочередно и добавлять в сводную таблицу. Что мы и сделали:
| Keyword | Keyword Difficulty |
| relationship memes | 3.99 |
| funny relationship memes | 2.51 |
| sad relationship quotes | 11.26 |
| relationship memes for him | нет данных |
| stages of a relationship | нет данных |
| cute names to call your girlfriend | 6.76 |
| questions to ask your girlfriend | 8.33 |
| nicknames for boyfriend | нет данных |
| how to stop thinking about someone | 7.26 |
| types of hugs | нет данных |
longtailpro.com
Вставляем все запросы в поле:
жмем “retrieve”. Получаем данные:
Переходим к последнему инструменту …
kwfinder.com
Процесс идентичен предыдущим. Вбиваем запрос, выбираем регион:
смотрим результат:
Неудобства:
1. нельзя загрузить список запросов и снять для них результат;
2. если вы хотите посмотреть низкочастотные запросы по какому-то направлению и увидеть сразу для них конкуренцию, то у вас это не получится:
3. нужно кликать на каждую иконку и только тогда сервис покажет:
Это крайне нелепо, так как если вы хотите экспортировать запросы в таблицу, то они все будут без KD.
Данные по нашим запросам:
| Keyword | Keyword Difficulty |
| relationship memes | 32 |
| funny relationship memes | 20 |
| sad relationship quotes | 25 |
| relationship memes for him | 19 |
| stages of a relationship | 33 |
| cute names to call your girlfriend | 13 |
| questions to ask your girlfriend | 9 |
| nicknames for boyfriend | 13 |
| how to stop thinking about someone | 42 |
| types of hugs | 32 |
Сравнение сервисов по анализу конкуренции запросов в США
| Keyword | Volume | KD Semrush | KD Ahrefs | KD Serpstat | KD Longtail | KD Kwfinder |
| relationship memes | 60500 | 67.39 | 4 | 3.99 | 36 | 32 |
| funny relationship memes | 14800 | 58.55 | 3 | 2.51 | 28 | 20 |
| sad relationship quotes | 4400 | 61.12 | 1 | 11.26 | 34 | 25 |
| relationship memes for him | 2400 | 57.35 | 6 | нет данных | 29 | 19 |
| stages of a relationship | 8100 | 68.51 | 22 | нет данных | 39 | 33 |
| cute names to call your girlfriend | 8100 | 57.94 | 4 | 6.76 | 16 | 13 |
| questions to ask your girlfriend | 22200 | 50.49 | 9 | 8.33 | 20 | 9 |
| nicknames for boyfriend | 22200 | 58.20 | 4 | нет данных | 17 | 13 |
| how to stop thinking about someone | 4400 | 60.16 | 9 | 7.26 | 34 | 42 |
| types of hugs | 1900 | 48.60 | 0 | нет данных | 27 | 32 |
Какие выводы можно сделать из этой таблицы?
- Сервисы заявляют, что используют диапазон от 1 до 100, но как правило задействуют его малую часть. Становится менее удобно пользоваться.
- Ahrefs, serpstat, весьма плохо работают с низкоконкурентными запросами:
- для одних запросов нет данных;
- для других — шаг оценки очень мал.
Оба сервиса не так давно запустили этот функционал, уверен, он еще будет дорабатываться.
semrush.com, longtailpro.com, kwfinder.com — будем сравнивать с ручным анализом топа.
Ручной анализ ТОП-10 выдачи по ключевым запросам в США
Формируем таблицу:
из checktrust.ru выгружаем нужные для анализа параметры:
- возраст;
- трафик;
- Trust Flow по majestic:
получаем данные:
экспортируем и добавляем в таблицу:
на что смотрим в выдаче:
- наличие молодых сайтов;
- смотрим есть ли у них трафик, если чектраст отдает 0, это не факт, проверяем руками в similarweb.
Вследствии изучения выделяем самые неконкурентные кластеры и смотрим, на сколько ваши выводы совпадают с оценкой анализаторов конкуренции, чтобы в следующий раз можно было использовать именно его.
При входе в новую нишу рекомендую делать такой рессеч, так как анализаторы работают лучше/хуже в зависимости от ниши.
Как правило, мы смотрим именно на longtailpro.com и на semrush.com.
Но всегда изучаем руками выдачу, если ниша для нас новая.
Да, я понимаю, что вы на этом шаге хотели бы получить однозначную рекомендацию, на какую единую цифру смотреть, но мы оставим это решение для вас.
Приоритезировав кластеры, переходим к сбору запросов.
Сбор запросов
Фух…разобрались с конкуренцией запросов. Наконец-то можно и сбором заняться.
Есть несколько основных источников:
- Google Keyword Planner, он же Планировщик ключевых слов Гугл;
- поисковые подсказки:
- Google;
- Amazon;
- Youtube;
- Ebay.
На масштабе работать с запросами все также удобно в Кей-Коллекторе.
Но сейчас мы рассмотрим более точечный вариант — сбор запросов для одной статьи из разных источников.
Например, возьмем запрос “how to stop thinking about someone”.
Шаг 1
Выгружаем производные запросы от главного из semrush:
(всего 9 запросов)
и добавляем в гугл таблицу:
Semrush, serpstat и другие сервисы в первую очередь берут запросы из Google Keyword Planner, но отдают вам гораздо быстрей. Особенно это удобно, если вы используете КейКоллектор в паре с одним из сервисов.
Шаг 2
Выжимаем максимум из semrush и конкурентов.
Смотрим органическую выдачу по главному запросу кластера:
Наша задача — посмотреть запросы, по каким еще запросам ранжируются эти страницы и расширить нашу семантику:
390 запросов против 9, которые были ранее. Неплохо.
Смотрим полный список запросов и выписываем уникальные слова, либо полные запросы в наш гугл док:
Отсортируем по частоте запросов и посмотрим, что еще мы можем для себя взять.
Важно! У нас не стоит задача все 300 запросов вписать в статью. Если изучаемая статья ранжируется на 30-100 позициях по каким-то запросам — это значит, что скорее всего они нам не подходят.
Отмеченные запросы не подходят для того, чтобы включить их в наше ТЗ, так как их частотность и конкуренция заслуживает того, чтобы под них написать отдельные статьи:
находя такие запросы, выписываем их в отдельный документ.
После рессеча конкурентов у нас в таблице появляется еще одна колонка запросов:
Наша задача на этом этапе — найти максимально уникальные запросы, которые у нас упущены в правой части.
Важно! Не старайтесь собрать сотни запросов, хороший автор не то, что не сможет вписать их в статью, он не возьмется за такое ТЗ.
Шаг 3
Подсказки поисковых систем, как правило, могут дать еще +10% интересных запросов. Однако, если первые 2 шага позволили вам собрать достаточно целевых запросов — от этого шага можно отказаться.
Да. Именно отказаться.
У нас не стоит задача собрать максимально все возможные запросы и любым образом вписать их в текст. Задача — использовать максимально возможное количество запросов, при котором автор сможет написать хорошую статью.
Для сбора подсказок рекомендую использовать KeyCollector, либо онлайн инструмент — Kparser, он позволяет собирать актуальные подсказки из разных источников:
Вводим наш запрос:

Ждем, пока спарсятся подсказки, изучаем выборку и добавляем их в нашу таблицу:
Данный метод очень хорошо подходит, когда вы работаете с нишами, где спрос только формируется и в serpstat, semrush, еще нет большого количества запросов.
При работе на рынках со сформированным спросом, этот шаг не всегда нужен.
Шаг 4
Еще один метод расширить семантику — LSI фразы.
Используем популярный инструмент — lsigraph.com
Как видим, запросы весьма далеки от нашего целевого, но все же несколько запросов можем добавить в нашу таблицу.
По итогу наша таблица сейчас выглядит так:
Переходим уже к шагу формирования ТЗ для копирайтера.
Готовы?
На самом деле, выбора у вас нет😅
Двигаемся дальше…
Формирование ТЗ для копирайтера
Наша задача на текущем этапе:
- выделить главные запросы, которые будут использоваться в подзаголовках статьи;
- задать базовую структуру статьи (для этого смотрим структуру конкурентов);
- оставить вспомогательные запросы и LSI фразы;
- подбираем хорошие статьи по теме в качестве примера для копирайтера.
Особых хитростей здесь нет.
Шаг 1
Запросы разделяем на 3 группы:
- общая;
- с негативным смыслом;
- с позитивным смыслом.
Оставляем уникальные запросы и слова:
Подбираем лучшие статьи в нише:
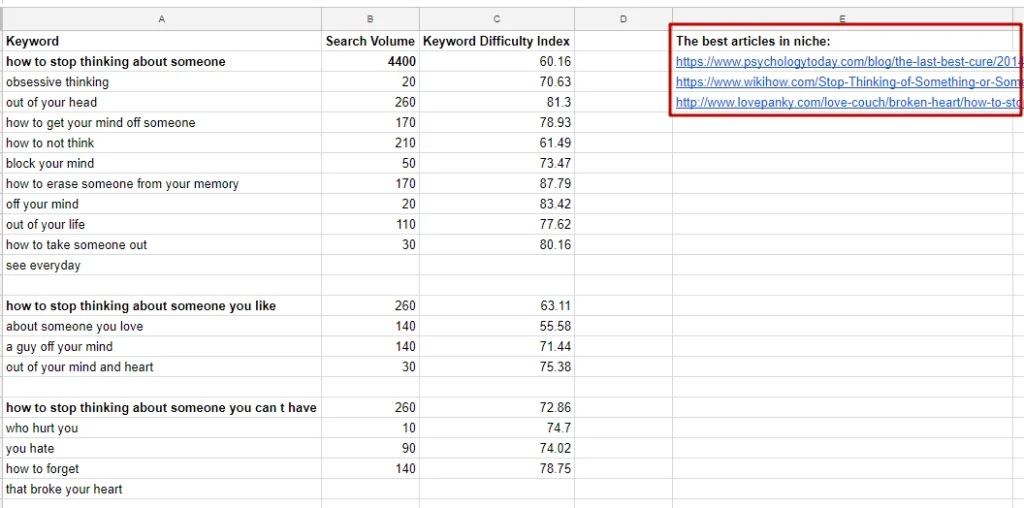
Добавляем мета-теги:
Рекомендуемый объем:
https://docs.google.com/spreadsheets/d/1OqqJH3cvYfTQKaiZRdGiMWRQOHK7e2-iRmjvl8RC_h8/edit#gid=0
ТЗ готово!
Как определить объем статьи?
Можно, конечно, считать по ТОПу среднее арифметическое.
Но давайте честно.
Это бесполезная трата времени!
Во-первых, топ постоянно меняется. Значит и среднее арифметическое будет постоянно меняться.
Во-вторых, нам нужно сделать лучшую статью в нише, а значит она должна быть больше.
Поэтому лучший алгоритм — на глаз:
- смотрим ТОП;
- понимаем формат материала;
- смотрим ТЗ;
- понимаем объем (минимум 500 слов на один раздел статьи);
- даем объем в диапазоне, чтобы у копирайтера была свобода действий и желание сделать хорошую статью, а не вписаться в нужное количество знаков.
ТЗ созданные по такой технологии дают должную свободу авторам для создания хорошей статьи, а значит и поисковая система получает то, что ей нужно — качественный контент. Оптимизатор — получает позиции и трафик.
Post Views: 60
 ru
ru























































